翻訳
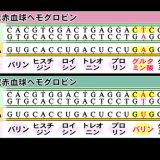
mRNAからタンパク質を合成することを翻訳と呼ぶ。タンパク質は20種類のアミノ酸が様々な配列で結合することによって合成される。mRNAの塩基3つの配列が1つのアミノ酸を指定している。
例:CCA → プロリン(アミノ酸)
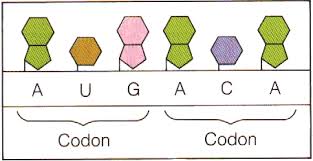
3つの塩基配列のことをトリプレットと呼ぶ。トリプレットの内、mRNAのトリプレットをコドンと呼んでいる。
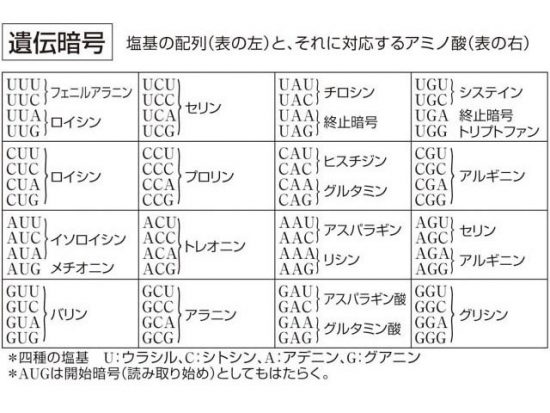
遺伝暗号表
コドンは4種類の塩基(A、U、G、C)から構成された3つの塩基配列であるので、その組み合わせは4×4×4=64通りある。この64通りの塩基配列がどのアミノ酸に対応するかを示した表を、遺伝暗号表と呼ぶ。AUGはメチオニンを指定し、タンパク質の合成開始も意味するので開始コドンと呼ぶ。UAA、UAG、UGAはアミノ酸指定はなく、タンパク質合成終了を示すので終始コドンと呼ぶ。
遺伝暗号の解読
ニーレンバーグはウラシル(U)だけを持つmRNAを合成し、大腸菌にの細胞抽出液に添加した。すると、フェニルアラニンだけによって構成されたポリペプチド鎖が合成された。このことから、UUUがフェニルアラニンを示すことが判明した。また、コラーナは数種の塩基が規則正しく並んでいるmRNAを用いて同様の実験を行い、コドンの解読を進めていった(コラーナの実験)。その後、様々な科学者が人工mRNAを用いて分析し、64種類のコドンを解読した。

真核生物の翻訳の仕組み
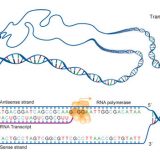
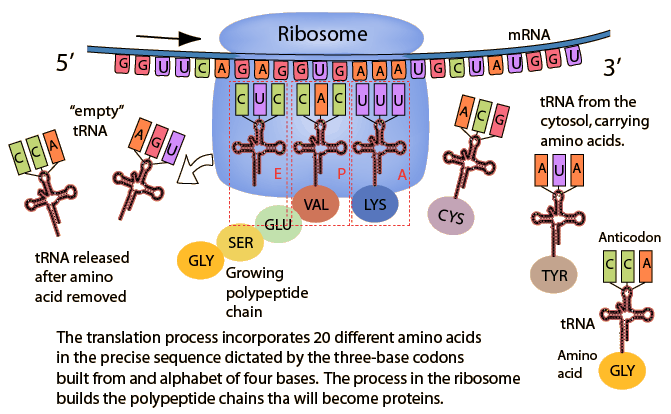
mRNAは核膜孔を通り、細胞質基質へ移動し、リボソームに付着する。リボソームでは、mRNAの塩基配列を元にtRNAがアミノ酸を運搬してくる。mRNAコドンに相補的な塩基配列を持つtRNAがリボソームに結合する。tRNAの3つの塩基配列をアンチコドンと呼ぶ。運搬されたアミノ酸はペプチド結合し、ペプチド鎖が合成される。
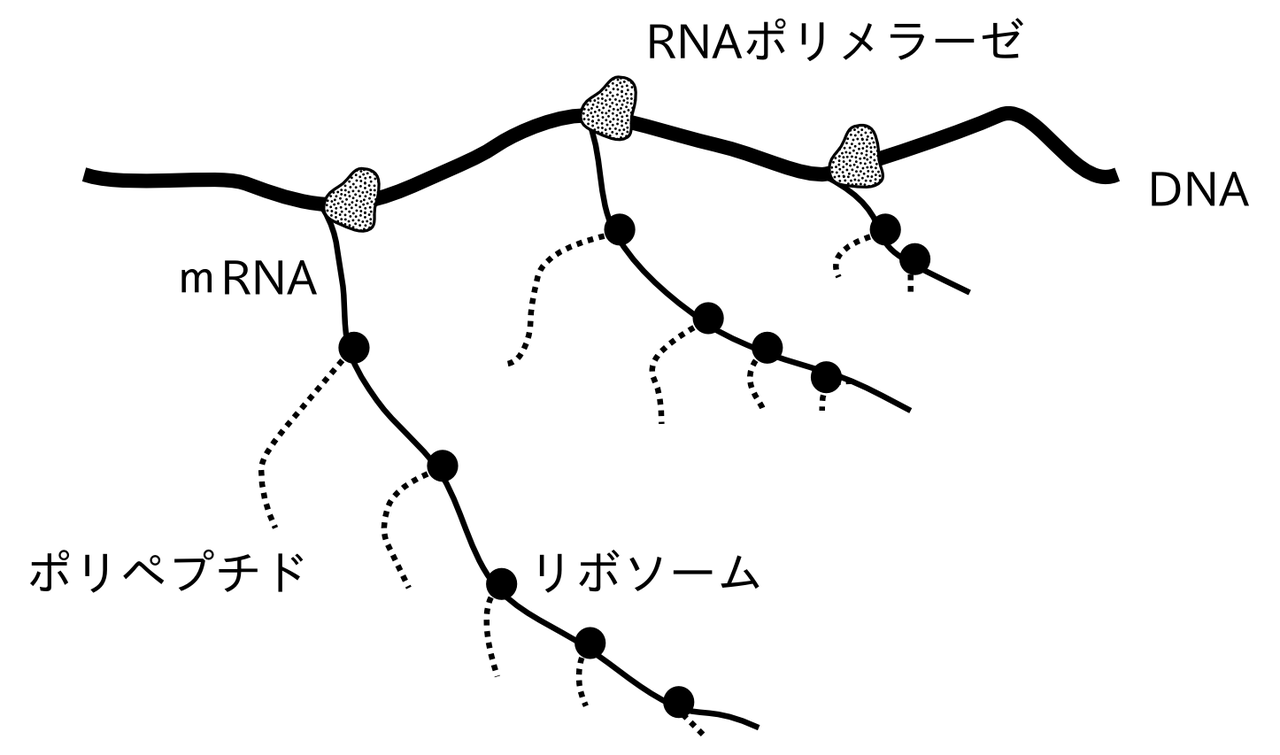
原核生物の翻訳の仕組み
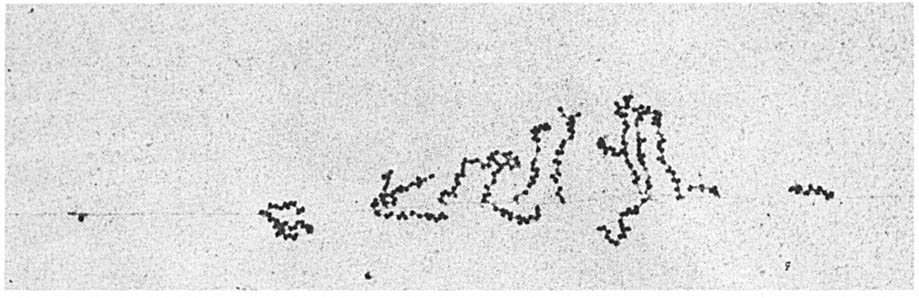
原核生物のDNAにはイントロンは存在しないため、スプライシングが起こらず、直接mRNAが合成される。また、核膜がないため、転写をしている最中にリボソームがmRNAに次々に付着し翻訳が始まる(下画像)。
http://www.neg-threequarters.jp/
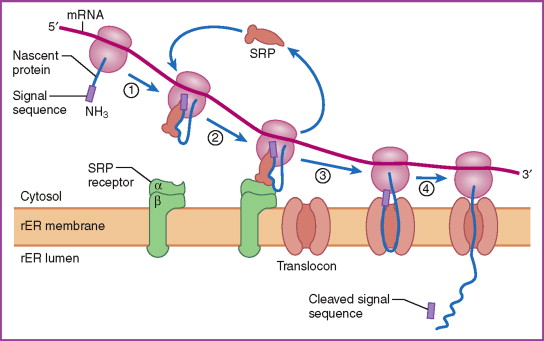
Advance:リボソームの小胞体への移動とSRP
リボソームには細胞質基質中に存在するものと、粗面小胞体上に存在するものがある。リボソームは細胞質基質から粗面小胞体上へと移動することがわかっている。

リボソームで合成されるポリペプチドには、最初に翻訳される側にシグナル配列と呼ばれるアミノ酸の配列が存在する。シグナル配列はSRP(シグナル認識粒子)と呼ばれるタンパク質が結合する領域であり、SRPがシグナル配列に結合すると翻訳が一時中断される。
SRPをつけたリボソームは自由に移動していくが、小胞体膜上のSRP受容体に結合すると、SRPは離れていく。その結果、翻訳が再開され、合成されたタンパク質が粗面小胞体の中に取り込まれていく。